理解常见的字符编码方案
什么是字符编码
为了便于在计算机中存储、传输和转换我们使用的图形字符,尤其是书面字符,设计者们给每个字符分配一个数字来代表它,这个过程就是字符编码(character encoding)。[1]
伴随着计算机的普及和相关技术的发展,在计算机领域曾先后产生了多个国际标准的字符编码系统以及各个国家自己的国家标准编码系统,下面记述的都是开发中常见的一些字符编码方案。
ASCII
ASCII /ˈæski/ (American Standard Code for Information Interchange),即美国信息交换标准码,是由美国国家标准协会于 1963 年首次发布的一套编码标准,它先后于 1967 年、1986 年获得过两次更新。
技术上,ASCII 采用统一的 7 位二进制位编码了 128 个字符(实际上存储时通常占用 8 位空间)。
- 0~31 & 127 号编码共 33 个控制字符;
- 32~126 号编码剩余的可打印字符。
后来,基于 7 位的 ASCII 标准又出现了多个互不兼容的 8 位编码的 Extended ASCII,比如在微软 Windows 95 和 Windows NT 系统上使用的 the ANSI character set,该编码后来也被称为 Windows-1252,数字 1252 代表的是 代码页 标识符,用以标记不同的字符集,比如这里的 1252 表示的就是西欧语言,此外还有 Windows-1256 表示阿拉伯语等。
你可以在 这里 查阅 ASCII 和 Windows-1252 的对照关系表。
GB 2312
GB 2312 (《信息交换用汉字编码字符集 基本集》) 是由我国国家标准部门于 1980 年 3 月 9 日发布,1981 年 5 月 1 日开始正式实施的简体中文编码方案,它一共收录了 6763 个汉字,基本满足了我们的日常使用。
WARNING
自 2017 年 3 月 23 日起,该标准才转为推荐性标准,编号也由 GB 2312-80 改为 GB/T 2312-1980,在浏览器编码表中由 GB2312 表示。
GB 2312 采用双字节,并以分区的形式来编码字符,高位字节表示区号,低位字节则用来编码该区内的不同字符,称作位。区和位都是从 1 开始计数的,二者共同组成了一个字符的区位号,或称区位码。
以区位码是 28-10 的 吉 字为例,其编码如下图所示:
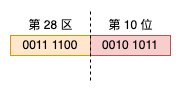
从图中可以看到“吉”字的区编码是 (0011 0001)2 = (60)10,但是为什么说它位于第 28 区呢?这是为了避开 ASCII 中 0~31 的控制字符以及 32 这个空格,第一个区就从 (0010 0001)2 开始编码,同理,表示位的低位字节也是从 (0010 0001)2 开始编码的。
GB 2312 的编码被称为国标码,但在计算机中实际存储时采用的并非国标码,而是转换为 EUC 编码,具体做法就是每个字符的区号和位号分别加上 0xA0 转成机内码,吉 字的机内码就是 0xA0 + 28, 0xA0 + 10,即 0xBCAA。
有关中文字符编码的更多信息,可参阅这篇文章 关于我国字符编码字符集介绍。
Unicode
为了“大一统”字符编码规则,1988 年几家计算机公司聚在一起,着手开发制定名为 Unicode 的国际标准。要想理解 Unicode 的编码机制,首先要了解一下 Unicode 的字符编码模型,该模型主要由下面将要介绍的四个层层递进的概念组成。
1. 抽象字符表
抽象字符表(Abstract Character Repertoire, ACR)表示 Unicode 要编码的字符集合。
Unicode 涵盖了世界上所有书写系统的所有字符,截止到 V15.0,共包含 149,186 个字符。[2]
2. 编码字符集
编码字符集(Coded Character Set, CCS)指的是抽象字符表 ACR 中的字符到非负整数的映射,每个字符对应的整数通常被称为该字符的 码点(Code Point)。
对于码点布局,Unicode 采用分组的方式编排字符,每组称为一个平面(Plane),从 0 开始计数,共有 17 个平面,每个平面包括 216 = 65,536 个码点。0 号平面定义了最常用的字符,所以又称基本多文种平面(Basic Multilingual Plane, BMP),其他平面都是辅助平面,但是也各有自己的名称,有关更多信息可参阅 Unicode 字符平面映射。
目前,Unicode 的码点范围或代码空间(Codespace)是 0x0……0x10FFFF,通常使用 U+十六进制码点值 来表示一个字符的 Unicode 代码,最少 4 个数字,不够的采用前导 0 补充,例如“吉”字的 Unicode 码是 U+5409,大写字母 A 的 Unicode 码是 U+0041。按照码点范围,Unicode 可以定义 1,114,112 个字符,但是 U+D800……U+DFFF 范围内的码点不对应任何字符,所以只能定义 1,114,112 - 2048 = 1,112,064 个字符。[3]
3. 字符编码表
字符编码表(Character Encoding Form, CEF)指的是编码字符集 CCS 中的非负整数到若干个固定长度的 01 串的映射,这个固定长的单位被称为代码单元(Code Unit)。一个给定的 CEF 中的码元的位数是固定的,但是一个字符对应的码元的个数则既可以是固定的,也可以是变化的。
- UTF-8 的 CEF 是可变长的,在 Unicode 中,1 到 4 个 8-bit 码元。
- UTF-16 的 CEF 是可变长的,在 Unicode 中,1 到 2 个 16-bit 码元。
- UTF-32 的 CEF 是固定宽度的,1 个 32-bit 码元。
4. 字符编码方案
字符编码方案(Character Encoding Scheme, CES)指的是一个字符的码元序列到字节序的可逆转换方案,包括以下 3 种方式:
- Simple CES: 每个 CEF 中的代码单元都与一个唯一字节序对应,UTF-8 采用这种方式。
- Compound CES: 使用两个或两个以上的 Simple CES 编码字符,外加一个在这些方案之间进行切换的机制,UTF-16、UTF-32 采用的就是这种方案。
- Compressing CES(暂不了解)
UTF-8
UTF-8 是目前最流行的字符编码系统,也是万维网使用的最主要的编码方式。如上所述,UTF-8 采用可变长的编码方式,它使用 1~4 个字节的位宽编码字符,具体规则如下图所示:
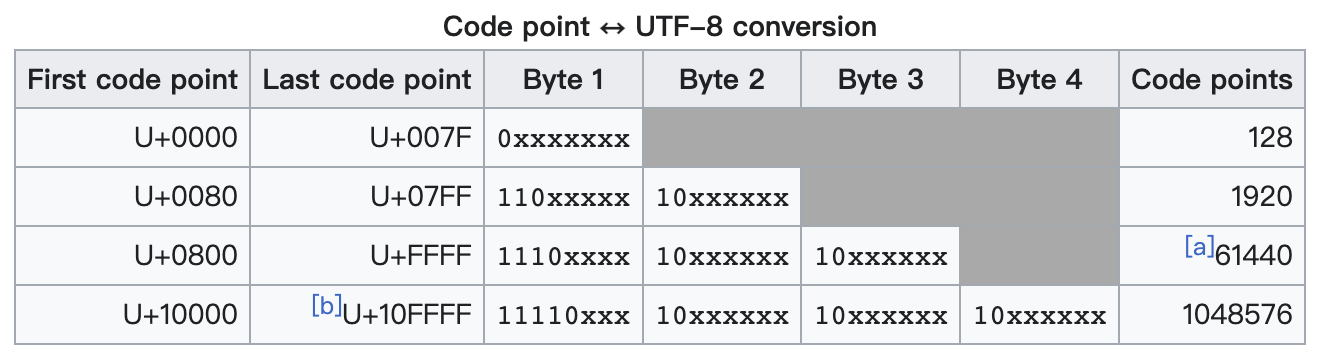
其中 U+0000……U+007F 码点范围内是单字节字符,向后完全兼容 ASCII。
不知道你有没有这样的疑惑:在解码一段使用 UTF-8 编码的文本时,系统是如何区别单字节字符和多字节字符的,比如遇到两个字节时,是把它当成一个整体来对待,还是当成两个独立的个体来对待?从上表可以看出,不同个数的码元的开头部分都各不相同,这样的设计就解决了这个问题。
UTF-16 & UTF-32
跟 UTF-8 一样,UTF-16 也是采用变长的 CEF,但它只有 2 个字节和 4 个字节的区分。
在 BMP 平面内的字符使用 2 个字节编码,规则也很简单,字节序的值等于码点的值。
在 SMP 平面内的字符使用 4 个字节编码。SMP 的数量是 16 个,即 24,每个平面 216 个字符,所以辅助平面共可以编码 U+D800……U+DBFF,构成字节序的前两个字节,第二部分(低字节)的 10 位映射到 U+DC00……U+DFFF,构成字节序的后两个字节,正好 4 个字节(前文提到过,U+D800……U+DFFF 码点范围内不映射任何字符)。映射算法如下所示:
// Taken from https://dmitripavlutin.com/what-every-javascript-developer-should-know-about-unicode
function getSurrogatePair(astralCodePoint) {
let highSurrogate = Math.floor((astralCodePoint - 0x10000) / 0x400) + 0xd800;
let lowSurrogate = ((astralCodePoint - 0x10000) % 0x400) + 0xdc00;
return [highSurrogate, lowSurrogate];
}
getSurrogatePair(0x1f600); // => [0xD83D, 0xDE00] => 😀
function getAstralCodePoint(highSurrogate, lowSurrogate) {
return (highSurrogate - 0xd800) * 0x400 + lowSurrogate - 0xdc00 + 0x10000;
}
getAstralCodePoint(0xd83d, 0xde00); // => 0x1F600 => 😀UTF-32 的编码规则最为简单,所有的字符统一使用固定的 4 个字节编码,字节序值等于相应的码点值。
BOM (Byte Order Mark)
计算机在处理多字节数据时,需要明确数据内部在内存中存储的字节顺序:
- 高位字节存储在低地址处,低位字节存储在高地址处,称之为 大端法。
- 反之,高位字节存储在高地址处,低位字节存储在低地址处,称之为 小端法 。
一款机器采用哪种字节序通常与处理器架构相关,即主机字节序。此外,网络协议也指定了网络传输过程中所采用的网络字节序,对于 TCP/IP 协议族,它使用的是符合人类书写习惯的大端法。
如前所述,UTF-16、UTF-32 的 Code Unit 都不是单个字节,因此在解释使用它们编码的字节串时,需要首先知道字节的顺序。单纯的 UTF-16 和 UTF-32 编码顺序使用文本开头的字节序标志 (Byte Order Mark, BOM) 来区分文本的字节序,这个标志使用了码点为 U+FEFF 的这个特殊字符,具体规则可参见 官方文档 。请注意,这里为什么要用“单纯”来形容?因为除了 UTF-16,还有 UTF-16BE 和 UTF-16LE,UTF-32 同理。它们之间的区别参见 Q: What are some of the differences between the UTFs?。
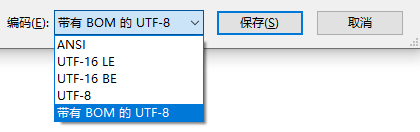
鉴于 UTF-8 的编码特性,标准的 UTF-8 是不带 BOM 的,但是如果你在 Windows 的记事本中另存为一个文件时,在可选的编码中你会发现一个叫作“带有 BOM 的 UTF-8”的编码方式。一旦你选择了它,那么这个另存为的文本文件就会变成带 BOM 的 UTF-8 编码的了。它背后其实是在文本的开头加上了 U+FEFF 的 UTF-8 编码 0XEFBBBF 这 3 个字节的数据。
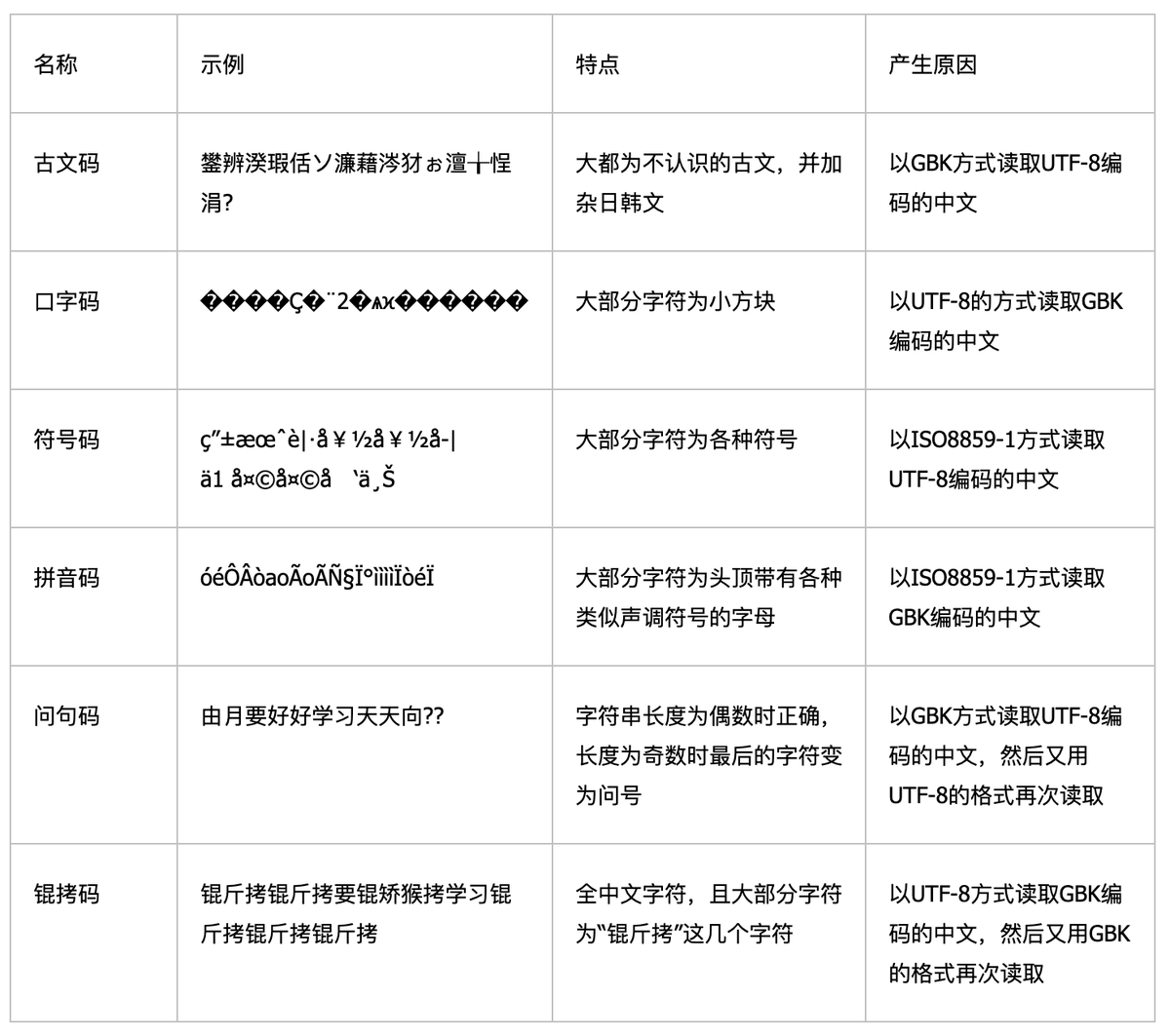
乱码问题
扩展阅读
- (译)2023 年每个软件开发者都必须知道的关于 Unicode 的最基本的知识(仍然不准找借口!)
- Unicode 与 JavaScript 详解
- MySQL 数据库 varchar 到底可以存多少个汉字,多少个英文呢?我们来搞搞清楚
维基百科 Character encoding ↩︎